mysql主从延迟解决方法
一、MySQL的数据库主从复制原理
MySQL主从复制实际上基于二进制日志,原理可以用一张图来表示:
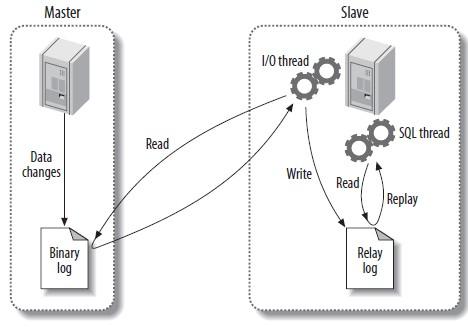
分为四步走:
主库对所有DDL和DML产生的日志写进binlog;
主库生成一个 log dump 线程,用来给从库I/O线程读取binlog;
从库的I/O Thread去请求主库的binlog,并将得到的binlog日志写到relay log文件中;
从库的SQL Thread会读取relay log文件中的日志解析成具体操作,将主库的DDL和DML操作事件重放。
关于DDL和DML
SQL语言共分为四大类:查询语言DQL,控制语言DCL,操纵语言DML,定义语言DDL。
DQL:可以简单理解为SELECT语句;
DCL:GRANT、ROLLBACK和COMMIT一类语句;
DML:可以理解为CREATE一类的语句;
DDL:INSERT、UPDATE和DELETE语句都是;
DDL和DML
DDL (Data Definition Language 数据定义语言)
create table 创建表
alter table 修改表
drop table 删除表
truncate table 删除表中所有行
create index 创建索引
drop index 删除索引 当执行DDL语句时,在每一条语句前后,oracle都将提交当前的事务。如果用户使用insert命令将记录插入到数据库后,执行了一条DDL语句(如create table),此时来自insert命令的数据将被提交到数据库。当DDL语句执行完成时,DDL语句会被自动提交,不能回滚。
DML (Data Manipulation Language 数据操作语言) insert 将记录插入到数据库 update 修改数据库的记录 delete 删除数据库的记录 当执行DML命令如果没有提交,将不会被其他会话看到。除非在DML命令之后执行了DDL命令或DCL命令,或用户退出会话,或终止实例,此时系统会自动发出commit命令,使未提交的DML命令提交。
二、主从复制存在的问题
主库宕机后,数据可能丢失;
主从同步延迟。
三、MySQL数据库主从同步延迟产生原因
原因分析
MySQL的主从复制都是单线程的操作,主库对所有DDL和DML产生的日志写进binlog,由于binlog是顺序写,所以效率很高。Slave的SQL Thread线程将主库的DDL和DML操作事件在slave中重放。DML和DDL的IO操作是随即的,不是顺序的,成本高很多。另一方面,由于SQL Thread也是单线程的,当主库的并发较高时,产生的DML数量超过slave的SQL Thread所能处理的速度,或者当slave中有大型query语句产生了锁等待那么延时就产生了。
常见原因:Master负载过高、Slave负载过高、网络延迟、机器性能太低、MySQL配置不合理。
四、主从延时排查方法
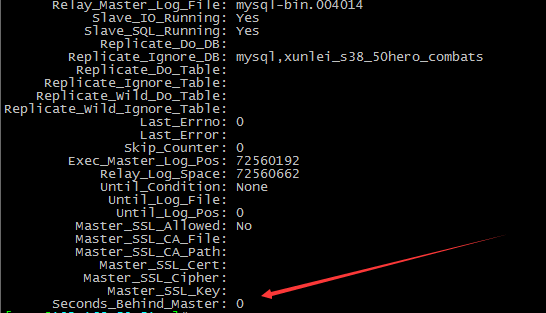
通过监控 show slave status 命令输出的Seconds_Behind_Master参数的值来判断:
NULL,表示io_thread或是sql_thread有任何一个发生故障;
0,该值为零,表示主从复制良好;
正值,表示主从已经出现延时,数字越大表示从库延迟越严重。
五、解决方案
解决数据丢失的问题:
- 半同步复制
从MySQL5.5开始,MySQL已经支持半同步复制了,半同步复制介于异步复制和同步复制之间,主库在执行完事务后不立刻返回结果给客户端,需要等待至少一个从库接收到并写到relay log中才返回结果给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一个TCP/IP往返耗时的延迟。
- 主库配置sync_binlog=1,innodb_flush_log_at_trx_commit=1
sync_binlog的默认值是0,MySQL不会将binlog同步到磁盘,其值表示每写多少binlog同步一次磁盘。
innodb_flush_log_at_trx_commit为1表示每一次事务提交或事务外的指令都需要把日志flush到磁盘。
注意:将以上两个值同时设置为1时,写入性能会受到一定限制,只有对数据安全性要求很高的场景才建议使用,比如涉及到钱的订单支付业务,而且系统I/O能力必须可以支撑!
解决从库复制延迟的问题:
优化网络
升级Slave硬件配置
Slave调整参数,关闭binlog,修改innodb_flush_log_at_trx_commit参数值
升级MySQL版本到5.7,使用并行复制
更多优化方案措施欢迎广大博友补充并纠正啦...
无论从事什么行业,只要做好两件事就够了,一个是你的专业、一个是你的人品,专业决定了你的存在,人品决定了你的人脉,剩下的就是坚持,用善良專業和真诚赢取更多的信任。
MySQL Proxy (是一个笨方法)
MySQL的主从同步机制非常方便的解决了高并发读的应用需求,给Web方面开发带来了极大的便利。但这种方式有个比较大的缺陷在于MySQL的同步机制 是依赖Slave主动向Master发请求来获取数据的,而且由于服务器负载、网络拥堵等方面的原因,Master与Slave 之间的数据同步延迟是完全没有保证的。短在1秒内,长则几秒、几十秒甚至更长都有可能。
由于数据延迟问题的存在,当应用程序在Master 上进行数据更新,然后又立刻需要从数据库中读取数据时,这时候如果应用程序从Slave上取数据(这也是当前Web开发的常规做法),就可能出现读取不到期望的数据,造成程序运行异常。
解决这个问题有多种方式,比如最简单的在所有的insert和update之后,强制sleep几秒钟。这是非常粗鲁的方式,对于更新操作不是很高的中小型系统,此方式基本能解决问题。
另外一种方式是应用程序把被更新的数据保存在本机的内存(或者集中式缓存)中,如果在写入数据完成后需要直接读取数据,则从本机内存中读取。这种方式的缺点是极大的增加了应用程序的复杂度,而且可靠性并不能完全得到保障。
使用MySQL Proxy可以很方便的解决这个问题。MySQL Proxy是基于MySQL Client 和 MySQL Server之间的代理程序,能够完成对Client所发请求的监控、修改。从Client角度看,通过Proxy访问Server和直接访问 Server没有任何区别。对于既有的程序而言,只要把直接被访问的Server的IP地址和端口号换成Proxy的IP地址和端口号就可以。
MySQL Proxy的工作原理也较简单。在Proxy启动时可以指定Proxy所需要使用的lua脚本,在lua脚本中预先实现6个方法:
* connect_server() // 接收到Client的连接请求时调用
* read_handshake() //
* read_auth() // 读取Client的认证信息时调用
* read_auth_result() // 读取认证结果时调用
* read_query() // 读取Client的query请求时调用
* read_query_result() //读取query结果时调用
当 Proxy接收到Client请求时,在请求的不同的阶段会调用上面的不同方法。这样Proxy使用者就可以根据自己的业务需求,自由的实现这6个方法达到目的。
通过在read_query()中加入代码,我们可以截取出当前的请求是insert、update还是select,然后把 insert和update请求发送到Master中,把select请求发送到Slave中,这样就解决了读写分离的问题。
在解决了读写分离后,如何解决同步延迟呢?
方法是在Master上增加一个自增表,这个表仅含有1个的字段。当Master接收到任何数据更新的请求时,均会触发这个触发器,该触发器更新自增表中的记录。如下图所示:

mysql_proxy_write
由于Count_table也参与Mysq的主从同步,因此在Master上作的 Update更新也会同步到Slave上。当Client通过Proxy进行数据读取时,Proxy可以先向Master和Slave的 Count_table表发送查询请求,当二者的数据相同时,Proxy可以认定 Master和Slave的数据状态是一致的,然后把select请求发送到Slave服务器上,否则就发送到Master上。如下图所示:

mysql_proxy_read
通过这种方式,就可以比较完美的结果MySQL的同步延迟不可控问题。之所以所“比较完美”,是因为这种方案double了查询请求,对 Master和Slave构成了额外的压力。不过由于Proxy与真实的Mysql Server采用连接池的方式连接,因此额外的压力还是可以接受的。